DP-900 Study Guide

Describe core data concepts (25–30%)
Describe ways to represent data
Features of Structured Data
Structured data refers to information with a high level of organization, such as that which is found in a relational database. It is characterized by the following features:
Predefined Schema: Structured data is organized according to a predefined schema. This schema dictates the structure of the data, including the data types and relationships between different data elements .
Easily Searchable: Due to its organized format, structured data can be easily searched and queried using standard query languages like SQL. This allows for efficient retrieval of data based on specific criteria .
Data Integrity: Structured data maintains data integrity through the use of constraints and rules that ensure the accuracy and consistency of the data. This includes primary keys, foreign keys, and other relational integrity constraints https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
Optimized for Performance: The storage and retrieval of structured data are optimized for performance. Indexing is commonly used to speed up data retrieval, making it ideal for applications that require quick access to large volumes of data https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
Standardized Format: The data is stored in tables with rows and columns, where each row represents a record and each column represents a data field. This standardized format makes it easier to share data across different systems and applications https://learn.microsoft.com/en-us/power-bi/guidance/powerbi-implementation-planning-usage-scenario-self-service-data-preparation .
Support for Complex Operations: Structured data supports complex operations such as joins, which allow for the combination of data from multiple tables. This is essential for applications that require relational data analysis https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
For more information on structured data and its features, you can refer to the following resources: - Real-Time Analytics in Fabric https://learn.microsoft.com/en-us/fabric/real-time-analytics/tutorial-introduction - Common Data Model (CDM) structure https://learn.microsoft.com/en-us/power-bi/guidance/powerbi-implementation-planning-usage-scenario-self-service-data-preparation - Azure Table storage https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview
This information can be used to understand the characteristics of structured data, which is a key concept in data fundamentals.
Describe core data concepts (25–30%)
Describe ways to represent data
Features of Semi-Structured Data
Semi-structured data is a type of data that does not conform to a rigid schema like traditional relational databases but still contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields. It is a form that lies between structured and unstructured data and is often represented in formats like JSON, XML, and YAML. Below are some key features of semi-structured data:
Flexible Schema: Semi-structured data does not require a predefined schema, allowing for the data structure to be defined on the fly. This flexibility is particularly useful when dealing with data that may have varying attributes or when attributes evolve over time https://learn.microsoft.com/en-us/fabric/get-started/decision-guide-data-store .
Self-Describing Nature: The data format often includes information about its own structure, which can be used to parse and understand the data without needing external metadata. This is achieved through the use of tags or other special characters .
Hierarchical Data Representation: It can represent complex hierarchical structures with nested objects, which is more difficult to achieve in a traditional tabular format. This makes it suitable for representing data like configuration files, web data, and complex data objects https://learn.microsoft.com/en-us/fabric/get-started/decision-guide-data-store .
Querying and Analysis: Semi-structured data can be queried and analyzed using specialized query languages. For example, the
??operator in KQL can be used to check for the presence of a property, assuming a default value if the property is not present https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/query/ternary-coalesce-operators . Similarly, PostgreSQL’s JSONB feature allows for querying JSON-formatted data efficiently https://learn.microsoft.com/en-AU/azure/cosmos-db/postgresql/quickstart-run-queries .Integration with Big Data Platforms: Semi-structured data is well-suited for big data platforms that can handle large volumes of diverse data. For instance, Real-Time Analytics in Microsoft Fabric can process structured, semi-structured, and unstructured data with high performance https://learn.microsoft.com/en-us/fabric/real-time-analytics/tutorial-introduction .
Use in NoSQL Databases: NoSQL databases like Azure Cosmos DB for PostgreSQL can store and manage semi-structured data, combining the power of SQL for structured data and the flexibility of NoSQL for semi-structured data https://learn.microsoft.com/en-AU/azure/cosmos-db/postgresql/quickstart-run-queries .
Custom Reporting: Semi-structured data can be used in custom reporting solutions that combine various Azure services to ingest, store, transform, and serve insights. This approach can leverage services like Azure Synapse Analytics and Fabric https://learn.microsoft.com/en-us/industry/well-architected/financial-services/analytics-data-estate .
For additional information on semi-structured data and its features, you can refer to the following resources: - Real-Time Analytics in Microsoft Fabric Overview https://learn.microsoft.com/en-us/fabric/real-time-analytics/tutorial-introduction . - Azure Synapse Analytics https://learn.microsoft.com/en-us/industry/well-architected/financial-services/analytics-data-estate . - Introduction to Lakehouse Architecture in Fabric https://learn.microsoft.com/en-us/industry/well-architected/financial-services/analytics-data-estate .
This information can be incorporated into a study guide to help learners understand the characteristics and advantages of semi-structured data in modern data platforms and analytics scenarios.
Features of Unstructured Data
Unstructured data refers to information that does not have a predefined data model or is not organized in a predefined manner. It is typically text-heavy, but may also contain data such as dates, numbers, and facts. Here are some key features of unstructured data:
Diverse Formats: Unstructured data comes in various formats, including text documents, images, videos, and social media posts. Unlike structured data, which fits neatly into a database, unstructured data is more free-form https://learn.microsoft.com/en-us/azure/azure-sql/migration-guides/database/sql-server-to-sql-database-assessment-rules https://learn.microsoft.com/en-us/azure/azure-sql/migration-guides/managed-instance/sql-server-to-sql-managed-instance-assessment-rules .
Storage and Management: Due to its nature, unstructured data is often stored on file systems like NTFS or in data lakes, which are designed to handle large volumes of diverse data https://learn.microsoft.com/en-us/azure/azure-sql/migration-guides/database/sql-server-to-sql-database-assessment-rules https://learn.microsoft.com/en-us/fabric/data-engineering/data-engineering-overview .
Volume: Unstructured data makes up a significant and ever-growing portion of the data generated today. It can be much larger in size and scale compared to structured data, requiring more storage space and processing power https://learn.microsoft.com/en-us/fabric/data-engineering/data-engineering-overview .
Analysis and Processing: Analyzing unstructured data often requires more advanced tools and techniques, such as natural language processing, machine learning, and big data analytics frameworks like Apache Spark https://learn.microsoft.com/en-us/fabric/data-engineering/data-engineering-overview https://learn.microsoft.com/en-us/fabric/data-science/model-training/model-training-overview .
Insights and Value: While it can be more challenging to process, unstructured data can provide valuable insights that are not available through structured data alone. This can include sentiment analysis from customer feedback, trend analysis from social media, or image recognition for medical diagnostics .
For additional information on unstructured data and its management within Microsoft technologies, you can refer to the following resources:
- Apache Spark in Microsoft Fabric for insights on machine learning with big data https://learn.microsoft.com/en-us/fabric/data-science/model-training/model-training-overview .
- Data Lakehouse Architecture for understanding how to store and manage structured and unstructured data in a single location https://learn.microsoft.com/en-us/fabric/data-engineering/data-engineering-overview .
Please note that while the FILESTREAM feature is commonly used to store unstructured data in the NTFS file system, it is not supported in Azure SQL Database or Azure SQL Managed Instance https://learn.microsoft.com/en-us/azure/azure-sql/migration-guides/database/sql-server-to-sql-database-assessment-rules https://learn.microsoft.com/en-us/azure/azure-sql/migration-guides/managed-instance/sql-server-to-sql-managed-instance-assessment-rules .
Describe core data concepts (25–30%)
Identify options for data storage
Common Formats for Data Files
Data files can come in various formats, each with its own structure and use cases. Below are some of the common data file formats:
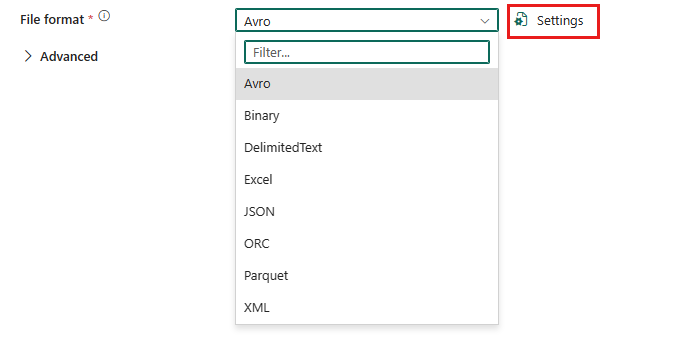
Avro
Apache Avro is a row-based format that is widely used within the Hadoop ecosystem. It is a compact, fast, binary data format that provides rich data structures with a robust schema. When configuring Avro in a data pipeline, you select Avro from the File format drop-down list in your connection settings and then configure specific settings for the format https://learn.microsoft.com/en-us/fabric/data-factory/format-avro .
Parquet
Parquet is a columnar storage file format optimized for use with big data processing frameworks. It is highly efficient for both storage and performance, especially when dealing with complex nested data structures. To configure Parquet format, you choose Parquet from the File format drop-down list in your data pipeline connection and adjust the settings accordingly https://learn.microsoft.com/en-us/fabric/data-factory/format-parquet .
Excel
Microsoft Excel format is commonly used for spreadsheet documents and supports data in tabular form. Excel files can be used as a source in data pipeline copy activities, where you can select Excel as the file format and configure additional settings as needed https://learn.microsoft.com/en-us/fabric/data-factory/format-excel .
JSON
JavaScript Object Notation (JSON) is a lightweight data-interchange format that is easy for humans to read and write, and easy for machines to parse and generate. JSON is often used for serializing and transmitting structured data over a network connection. In a data pipeline, JSON format can be selected from the File format drop-down list for further configuration https://learn.microsoft.com/en-us/fabric/data-factory/format-json .
Additional Configuration
For each of these formats, additional settings can be configured to tailor the data handling to specific requirements. This may include specifying the bucket or folder path for the data, as well as advanced settings for performance tuning and error handling https://learn.microsoft.com/en-us/fabric/data-factory/connector-google-cloud-storage-copy-activity .
For more detailed information on configuring these file formats, you can refer to the following resources: - Configure Avro format settings https://learn.microsoft.com/en-us/fabric/data-factory/format-avro - Configure Parquet format settings https://learn.microsoft.com/en-us/fabric/data-factory/format-parquet - Configure Excel format settings https://learn.microsoft.com/en-us/fabric/data-factory/format-excel - Configure JSON format settings https://learn.microsoft.com/en-us/fabric/data-factory/format-json
{kind=link}
Understanding these common data file formats and how to configure them is essential for managing and processing data effectively in various data pipeline scenarios.
Describe core data concepts (25–30%)
Identify options for data storage
Types of Databases in Azure
When discussing databases within the Azure ecosystem, it’s important to understand the various types of databases available and their respective use cases. Here are the primary types of databases you can work with in Azure:
Azure SQL Database
Azure SQL Database is a fully managed relational database with built-in intelligence supporting self-driving features such as performance tuning and threat alerts. It is based on the latest stable version of the Microsoft SQL Server database engine and is highly compatible with most SQL Server features. This service is a good choice for a wide range of applications, particularly when working with structured data and requiring complex queries and transactional support https://learn.microsoft.com/en-us/azure/azure-sql/database/file-space-manage .
Azure SQL Managed Instance
Azure SQL Managed Instance is an expansion of Azure SQL Database, designed to provide near 100% compatibility with the latest SQL Server (on-premises) database engine. It offers a fully managed instance that includes features like SQL Agent, Service Broker, and cross-database queries. This service is typically used when migrating an existing SQL Server environment to Azure with minimal changes https://learn.microsoft.com/en-us/azure/azure-sql/database/file-space-manage .
Azure Cosmos DB
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database service. It offers turnkey global distribution, supports document, key-value, graph, and column-family data models, and provides comprehensive service level agreements (SLAs). It’s a great option for applications that require a high level of scalability and responsiveness, and for those that deal with varied and evolving data schemas https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/couchbase-cosmos-migration .
Azure Synapse Analytics
Azure Synapse Analytics (formerly SQL Data Warehouse) is an analytics service that brings together big data and data warehousing. It allows you to query large volumes of data using either on-demand or provisioned resources. Synapse is not a database per se but integrates with databases and data lakes, providing a powerful platform for big data analytics https://learn.microsoft.com/en-us/azure/azure-sql/database/logins-create-manage .
Azure Database for MySQL, PostgreSQL, and MariaDB
These are fully managed database services for app developers, offering community versions of MySQL, PostgreSQL, and MariaDB with built-in high availability, security, and scaling on the fly with minimal downtime. These services are ideal for applications that are built on these open-source database engines and require a managed service with easy scaling, high availability, and security .
Azure Table Storage
Azure Table Storage is a service that stores large amounts of structured, non-relational data. It’s a NoSQL data store for semi-structured data. Azure Table Storage is a good choice for flexible datasets like user data for web applications, address books, device information, and other metadata .
For more detailed information on each of these database types, you can refer to the following URLs: - Azure SQL Database: Learn More - Azure SQL Managed Instance: Learn More - Azure Cosmos DB SDKs: Learn More - Azure Synapse Analytics: Learn More - Azure SQL Database Hyperscale: Learn More
Each of these database services offers unique features and capabilities that cater to different needs and scenarios. When choosing a database service for your application, consider factors such as the data model, scalability requirements, operational maintenance, and the specific features that your application needs.
Describe core data concepts (25–30%)
Describe common data workloads
Transactional workloads are characterized by their need for optimized data centers that prioritize low latency to handle quick and frequent data transactions. These workloads typically involve operations that require immediate processing, such as online transaction processing (OLTP) systems. The key features of transactional workloads include:
Low Latency: Transactional workloads require data centers that are optimized for low latency to ensure that transactions are processed as quickly as possible, providing a seamless experience for end-users https://learn.microsoft.com/en-AU/azure/cosmos-db/../managed-instance-apache-cassandra/best-practice-performance .
Separation from Analytical Workloads: Due to the differing requirements, transactional workloads are often handled in separate data centers from those used for analytical workloads, which tend to involve more complex and time-consuming queries https://learn.microsoft.com/en-AU/azure/cosmos-db/../managed-instance-apache-cassandra/best-practice-performance .
Operational Complexity: Managing transactional workloads can involve complex operations, especially when integrating with Extract-Transform-Load (ETL) pipelines for data analysis. This can add layers of data and job management, potentially impacting the performance of transactional systems https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link .
Performance Impact: Traditional methods of analyzing operational data from transactional workloads, such as ETL, can affect the performance of these critical systems and introduce latency in data analysis https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link .
For additional information on transactional workloads and their management within Azure services, you can refer to the following resources:
- Azure Cosmos DB: Azure Cosmos DB Documentation
- Azure Synapse Link for Azure Cosmos DB: Azure Synapse Link for Azure Cosmos DB Documentation
- Transactional and Analytical Workloads on Azure: Transactional and Analytical Workloads on Azure
Please note that the URLs provided are for reference purposes and are not meant to be included in the study guide as direct links.
Describe core data concepts (25–30%)
Describe common data workloads
Analytical workloads are designed to handle complex queries that often involve large volumes of data and require significant computational power to execute. These workloads are typically used for business intelligence (BI), reporting, and data analysis purposes. Here are some key features of analytical workloads:
Scalability and Elasticity
Analytical workloads must be able to scale to accommodate large datasets and varying levels of demand. This means that the underlying infrastructure should be able to handle an increase in data volume and query complexity without a degradation in performance https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link .
Performance Optimization
The systems that support analytical workloads are optimized for high performance. This includes specialized storage technology that is self-managed and designed to optimize analytics workloads, ensuring that queries are executed efficiently https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link .
Integration with Analytical Tools
Analytical workloads often require integration with analytical tools and platforms. Azure Cosmos DB, for example, has built-in support for Azure Synapse Analytics, which simplifies access to the storage layer and enhances performance for analytical tasks https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link .
Active-Active Workload Management
Modern databases like Azure Cosmos DB allow for the running of globally distributed analytical workloads alongside transactional workloads in an active-active configuration. This means that analytical queries can be run effectively against the nearest regional copy of the data, reducing latency and improving query performance https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link .
Read Replica Utilization
For read-intensive analytical workloads, the use of read replicas can improve performance and scalability. By isolating read workloads to replicas and directing write workloads to the primary source, systems can handle higher volumes of read operations without impacting the write capacity. This is particularly useful for BI and reporting purposes, where the data source is primarily read-only https://learn.microsoft.com/en-AU/azure/mysql/single-server/concepts-read-replicas https://learn.microsoft.com/en-AU/azure/mariadb/concepts-read-replicas .
It’s important to note that while read replicas enhance read performance, they do not directly reduce write-capacity burdens on the primary source and are not suitable for write-intensive workloads. Additionally, there is an inherent delay in data replication, so read replicas are best used for workloads that can accommodate this latency https://learn.microsoft.com/en-AU/azure/mysql/single-server/concepts-read-replicas https://learn.microsoft.com/en-AU/azure/mariadb/concepts-read-replicas .
For more information on Azure Cosmos DB and its capabilities for analytical workloads, you can visit the following URL: Azure Cosmos DB.
Please note that the provided URL is for informational purposes and to offer additional resources for understanding analytical workloads in the context of Azure services.
Describe core data concepts (25–30%)
Identify roles and responsibilities for data workloads
Responsibilities for Database Administrators
Database Administrators (DBAs) play a critical role in managing and maintaining the integrity and performance of databases. Their responsibilities include, but are not limited to, the following areas:
Security Management: DBAs are responsible for ensuring the security of the database. This includes managing access controls, implementing Always Encrypted technology to protect sensitive data, and overseeing the roles of users who manage encryption keys, such as Security Administrators https://learn.microsoft.com/en-us/azure/azure-sql/database/always-encrypted-landing .
Performance Monitoring: Monitoring the performance of the database to ensure it runs efficiently and effectively is a key responsibility. This involves optimizing queries, indexing, and ensuring that the database is tuned for the workload it supports.
Backup and Recovery: DBAs must regularly back up the database and ensure that recovery procedures are in place and tested. This is crucial for protecting data against loss or corruption.
User and Permission Management: Managing user access to the database is essential. This includes creating and maintaining user accounts, assigning appropriate permissions, and ensuring that users have the necessary access to perform their roles .
Automation of Tasks: DBAs may use service principals or managed identities to automate tasks such as Microsoft Entra object creation in SQL Database, which allows for full automation of database user creation without additional SQL privileges https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing .
Governance and Compliance: Ensuring that the database complies with relevant laws and regulations is a critical responsibility. This includes data privacy laws and industry-specific regulations.
Maintenance and Updates: Regular maintenance of the database is required, including applying patches and updates to the database software to ensure it remains secure and efficient.
Troubleshooting and Support: DBAs are the first point of contact for any database-related issues. They must be able to troubleshoot problems and provide support to resolve issues quickly.
For additional information on the roles and responsibilities of database administrators, you can refer to the following resources:
Please note that the URLs provided are for reference purposes to supplement the study guide material.
Describe core data concepts (25–30%)
Identify roles and responsibilities for data workloads
Responsibilities for Data Engineers
Data Engineers play a crucial role in managing and optimizing data workflows and infrastructure within an organization. Their responsibilities include:
Data Architecture and Deployment Planning: Data Engineers are responsible for planning the deployment and architecture of data solutions. This involves integrating various services and data platforms to ensure seamless data flow and accessibility https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence .
Data Pipeline Development: They build and maintain the data pipelines that are essential for transporting data from various sources to storage solutions or for processing. This includes ensuring that data is collected, stored, and retrieved efficiently https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence .
Data Asset Publication: Publishing data assets that are used across the organization is another key responsibility. These assets can include lakehouses, data warehouses, data pipelines, dataflows, or semantic models, which form the backbone of the organization’s data infrastructure https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence .
Data Management: Data Engineers create and manage data assets to support self-service content creators. This includes tasks such as data modeling and ensuring the quality and consistency of shared data resources https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence .
Support and Troubleshooting: They provide user support by assisting with the resolution of data discrepancies and escalated help desk support issues. This ensures that any problems with data access or quality are quickly addressed https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence .
Compute Utilization and Reporting: In the context of Microsoft Fabric, Data Engineers are involved in compute utilization and reporting for Spark, which powers Synapse Data Engineering and Science workloads. They manage operations like table preview, load to delta, notebook runs, scheduled runs, and spark job definition runs https://learn.microsoft.com/en-us/fabric/data-science/../data-engineering/billing-capacity-management-for-spark .
Cost Management: Data Engineers also need to be aware of the capacity charges associated with their workspaces and how these are reflected in the Azure portal under the Microsoft Cost Management subscription. Understanding Fabric billing is important for managing the financial aspects of data operations https://learn.microsoft.com/en-us/fabric/data-science/../data-engineering/billing-capacity-management-for-spark .
For additional information on the roles and responsibilities of Data Engineers, you can refer to the following resources: - Data Engineering and Data Science in Microsoft Fabric https://learn.microsoft.com/en-us/fabric/data-science/../data-engineering/billing-capacity-management-for-spark - Roles within a Center of Excellence (COE) https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence
Please note that the scope of responsibilities for Data Engineers can vary significantly between organizations, and the roles may overlap with other positions within a Center of Excellence (COE) https://learn.microsoft.com/power-bi/guidance/fabric-adoption-roadmap-center-of-excellence .
Describe core data concepts (25–30%)
Identify roles and responsibilities for data workloads
Describe Responsibilities for Data Analysts
Data analysts play a crucial role in organizations by turning data into actionable insights. Their responsibilities often include the following:
Utilizing Semantic Models: Data analysts frequently use semantic models to interpret and analyze data. They typically have Read and Build permissions on these models, which allows them to create reports while ensuring that Row-Level Security (RLS) is enforced for both report creators and consumers https://learn.microsoft.com/en-us/power-bi/guidance/powerbi-implementation-planning-security-content-creator-planning .
Collaboration and Data Sharing: Analysts work closely with other roles, such as business users and data scientists, sharing Power BI reports and datasets to facilitate seamless collaboration. This inter-role cooperation is particularly beneficial during the problem formulation phase of projects https://learn.microsoft.com/en-us/fabric/data-science/data-science-overview .
Intra-team Support: Data analysts often engage in peer learning and support within their teams. They may voluntarily take on informal support roles, especially if they are recognized as subject matter experts or champions within their domain. This peer-to-peer learning is a significant aspect of workplace education and is particularly valuable for analysts working on domain-specific analytics solutions https://learn.microsoft.com/en-us/power-bi/guidance/fabric-adoption-roadmap-user-support .
Automated Machine Learning (AutoML): In environments that support Power BI Premium or Embedded capacities, data analysts may leverage AutoML for dataflows. This enables them to train, validate, and invoke machine learning models directly within Power BI, simplifying the process of creating new ML models using their dataflows https://learn.microsoft.com/en-us/power-bi/create-reports/../transform-model/dataflows/dataflows-machine-learning-integration .
Technical Enablement and Support: While the central BI team typically handles the technical aspects of Power BI as a platform, data analysts within distributed analytics groups focus on the content. They are subject matter experts who understand the business needs and work on analytics solutions pertinent to their specific business unit or shared services function https://learn.microsoft.com/en-us/power-bi/guidance/powerbi-migration-learn-from-customers .
For additional information on the roles and responsibilities of data analysts, you can refer to the following resources:
- Semantic Models in Power BI
- Collaboration in Microsoft Fabric
- Automated Machine Learning in Power BI
Please note that the URLs provided are for reference purposes to supplement the study guide content.
Identify considerations for relational data on Azure (20–25%)
Describe relational concepts
Features of Relational Data
Relational data refers to structured data that is organized into tables, which are known as relations. Each table contains rows and columns, where rows represent records and columns represent attributes of the data. Here are some key features of relational data:
Structured Query Language (SQL)
SQL is the standard language used to manage and manipulate relational databases. It allows users to perform various operations such as creating tables, inserting data, updating records, and querying data https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing .
Data Integrity
Relational databases enforce data integrity through constraints such as primary keys, foreign keys, unique constraints, and check constraints. These ensure the accuracy and consistency of the data within the database https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing .
Normalization
Normalization is a process used to organize data to reduce redundancy and improve data integrity. It involves dividing large tables into smaller, more manageable pieces while maintaining relationships between them .
Security Features
Relational databases provide several security features to protect data, including: - SQL Managed Instance auditing: Tracks database activities for compliance and security analysis https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing . - Always Encrypted: Helps protect sensitive data by encrypting it at the application layer, so the data is encrypted in transit, at rest, and during query processing https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing . - Threat detection: Identifies unusual activities that could indicate a security threat to the database https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing . - Dynamic data masking: Hides sensitive data in query results without changing the actual data stored in the database https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing . - Row-level security: Controls access to rows in a database table based on the characteristics of the user executing a query https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing . - Transparent data encryption (TDE): Encrypts the storage of an entire database by using a symmetric key called the database encryption key https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing .
Transaction Management
Relational databases support transactions, which are sequences of operations performed as a single logical unit of work. Transactions ensure that all operations within the unit are completed successfully before committing data to the database, maintaining data integrity https://learn.microsoft.com/en-us/azure/azure-sql/database/authentication-azure-ad-landing .
Indexing
Indexes are used to speed up the retrieval of rows from a database table. An index is created on columns that are used frequently in query predicates and join conditions .
Spatial Data Support
Relational databases like Azure SQL support spatial data types, which allow the storage and query of data related to the physical location and shape of objects. Azure SQL supports geometry and geography data types for Euclidean and round-earth coordinate systems, respectively https://learn.microsoft.com/en-us/azure/azure-sql/multi-model-features .
Multi-Model Capabilities
Modern relational databases support multi-model data processing, enabling the storage and management of different data types such as graph, JSON, spatial, and XML within the same database https://learn.microsoft.com/en-us/azure/azure-sql/multi-model-features .
Change Tracking and Data Capture
Change tracking and change data capture are features that allow applications to determine the changes that have occurred in the database so that they can respond accordingly. These features enable efficient data synchronization and auditing https://learn.microsoft.com/en-AU/azure/azure-sql-edge/track-data-changes https://learn.microsoft.com/en-AU/azure/azure-sql-edge/track-data-changes .
For additional information on these features, you can refer to the following resources: - SQL Managed Instance Security Features - Spatial Data in Azure SQL - Graph Processing in Azure SQL Database - JSON Data in SQL Server - Change Tracking in SQL Server - Change Data Capture in SQL Server
Identify considerations for relational data on Azure (20–25%)
Describe relational concepts
Normalization is a database design technique that organizes tables in a manner that reduces redundancy and dependency of data. It involves dividing a database into two or more tables and defining relationships between the tables. The main goal of normalization is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships .
There are several reasons why normalization is used:
To minimize data redundancy: Normalization helps to eliminate duplicate data, which not only reduces the storage space required but also ensures that data is consistent across the database .
To improve data integrity: By reducing redundancy, normalization helps maintain data integrity, as there is a single point of truth for each piece of information. This makes the database more accurate and reliable .
To enhance query performance: Well-normalized tables can lead to more efficient database queries. By organizing data in a way that eliminates unnecessary data duplication, queries can run faster because they have to process less data .
To facilitate easier database maintenance: Normalization simplifies the database structure, which makes it easier to maintain over time. Changes in one part of the database are less likely to have unwanted consequences in other parts, which can reduce the complexity of database maintenance tasks .
To avoid update anomalies: When data is duplicated and not properly managed, it can lead to inconsistencies known as update anomalies. Normalization helps to avoid these anomalies by ensuring that each piece of data is stored only once .
For additional information on normalization and its importance in database design, you can refer to the following resources:
- Normalization vs. denormalization in Azure Data Explorer https://learn.microsoft.com/azure/data-explorer/kusto/functions-library/pairwise-dist-fl .
- Understand star schema and the importance for Power BI, which discusses normalization in the context of data modeling for Power BI https://learn.microsoft.com/en-us/power-bi/create-reports/../natural-language/q-and-a-best-practices .
Please note that while normalization is beneficial for transactional databases, denormalization may sometimes be preferred for analytical databases to optimize query performance. It’s important to find the right balance for your specific use case https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/modeling-data .
Identify considerations for relational data on Azure (20–25%)
Describe relational concepts
Common Structured Query Language (SQL) Statements
Structured Query Language (SQL) is a standardized programming language used for managing and manipulating relational databases. Here are some common SQL statements that are essential for interacting with databases:
Data Definition Language (DDL)
DDL statements are used to define and modify the database structure or schema.
CREATE: This statement is used to create a new table, a view of a table, or other object in the database.
CREATE TABLE table_name ( column1 datatype, column2 datatype, ... );ALTER: Alters the structure of an existing database object, such as adding a column to an existing table.
ALTER TABLE table_name ADD column_name datatype;DROP: Deletes an entire table, a view of a table or other objects in the database.
DROP TABLE table_name;
Data Manipulation Language (DML)
DML statements are used for managing data within schema objects.
SELECT: Retrieves data from one or more tables.
SELECT column1, column2, ... FROM table_name;INSERT INTO: Inserts new data into a table.
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);UPDATE: Modifies existing data within a table.
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;DELETE: Removes data from a table.
DELETE FROM table_name WHERE condition;
Data Control Language (DCL)
DCL includes commands such as GRANT and REVOKE which mainly deal with the rights, permissions, and other controls of the database system.
GRANT: Gives user’s access privileges to the database.
GRANT privilege_name ON object_name TO {user_name | PUBLIC | role_name} [WITH GRANT OPTION];REVOKE: Withdraws user’s access privileges given by using the GRANT command.
REVOKE privilege_name ON object_name FROM {user_name | PUBLIC | role_name}
Transaction Control Language (TCL)
TCL statements are used to manage the changes made by DML statements.
COMMIT: Saves all the transactions to the database.
COMMIT;ROLLBACK: Restores the database to the last committed state.
ROLLBACK;SAVEPOINT: Sets a savepoint within a transaction.
SAVEPOINT savepoint_name;SET TRANSACTION: Places a name on a transaction.
SET TRANSACTION NAME transaction_name;
For more detailed information on SQL statements and their usage, you can refer to the following resources: - SQL Server Documentation - Azure SQL Database Documentation
Please note that the specific syntax for SQL statements can vary slightly between different database systems, but the fundamental concepts remain consistent.
Identify considerations for relational data on Azure (20–25%)
Describe relational concepts
Identify Common Database Objects
When working with databases, it is essential to understand the common objects that you will encounter. These objects are the building blocks of a database and are used to store and manage data. Below is an explanation of some of the most common database objects:
Databases
A database is a structured set of data held in a computer, especially one that is accessible in various ways. In the context of Azure Cosmos DB, a database can support one or more independent databases https://learn.microsoft.com/en-AU/azure/cosmos-db/mongodb/how-to-python-get-started .
Collections
In MongoDB, which is supported by Azure Cosmos DB’s API for MongoDB, a collection is a group of documents. It is analogous to a table in a relational database system. Collections do not enforce a schema, meaning that documents within a single collection can have different fields https://learn.microsoft.com/en-AU/azure/cosmos-db/mongodb/how-to-python-get-started .
Documents
A document is a set of key-value pairs and represents a single entry in a collection. Documents in MongoDB are similar to JSON objects but are stored in a format known as BSON. Documents have dynamic schemas, which means that documents in the same collection do not need to have the same set of fields, and common fields can hold different types of data https://learn.microsoft.com/en-AU/azure/cosmos-db/mongodb/how-to-python-get-started .
Tables
Tables are a type of database object that is used to store data in rows and columns. Each row in a table represents a unique record, and each column represents a field within the record. In Azure Cosmos DB, you can restore specific tables if needed .
Indexes
Indexes are used to speed up the retrieval of data from a database. They are created on columns in a table to allow for faster searches. Azure Cosmos DB allows you to script out existing indexes to view their definitions https://learn.microsoft.com/en-us/azure/azure-sql/identify-query-performance-issues .
For more information on working with these database objects in Azure Cosmos DB, you can refer to the following resources: - Azure Cosmos DB resource model for an overview of the hierarchy of resources https://learn.microsoft.com/en-AU/azure/cosmos-db/mongodb/how-to-python-get-started . - Working with collections and documents in MongoDB for details on managing collections and documents https://learn.microsoft.com/en-AU/azure/cosmos-db/mongodb/how-to-javascript-manage-databases . - Azure Storage redundancy for information on the durability and redundancy of Azure Storage, which is relevant for understanding the storage of database objects in Azure Cosmos DB https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Understanding these common database objects is crucial for anyone working with databases, as they form the foundation upon which data storage and retrieval are built.
Identify considerations for relational data on Azure (20–25%)
Describe relational Azure data services
Azure SQL Family of Products
The Azure SQL family of products offers a range of options for running SQL Server databases in the cloud, each tailored to specific needs and scenarios. Below is a detailed explanation of the three primary offerings: Azure SQL Database, Azure SQL Managed Instance, and SQL Server on Azure Virtual Machines.
Azure SQL Database
Azure SQL Database is a fully managed Platform-as-a-Service (PaaS) database engine that handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement. Azure SQL Database is always running on the latest stable version of SQL Server Database Engine and patched OS with 99.99% availability. It is best suited for modern cloud applications that require a scalable, managed database service.
- Built-in Intelligence: Azure SQL Database includes features like automatic performance tuning and threat detection.
- Scalability: Offers a single database with its own set of resources managed via SQL Database server or elastic pools which is a collection of databases with a shared set of resources.
- High Availability: Built-in high availability with a 99.99% availability SLA.
For more information on Azure SQL Database, visit Azure SQL Database Documentation.
Azure SQL Managed Instance
Azure SQL Managed Instance is an expansion of Azure SQL Database, providing a fully managed instance of the Microsoft SQL Server database engine. It provides near 100% compatibility with the latest SQL Server on-premises (Enterprise Edition) Database Engine, providing a native virtual network (VNet) implementation that addresses common security concerns, and a business model favorable for on-premises SQL Server customers.
- High Availability: Azure SQL Managed Instance features built-in high availability solutions deeply integrated with Azure, such as Service Fabric for failure detection and recovery, Azure Blob storage for data protection, and Availability Zones for higher fault tolerance https://learn.microsoft.com/en-us/azure/azure-sql/managed-instance/high-availability-sla .
- Compatibility: Supports the same compatibility levels and features available to single managed instances, making it suitable for most migrations to the cloud with minimal changes https://learn.microsoft.com/en-us/azure/azure-sql/database/monitoring-tuning-index .
- PaaS Benefits: Offers all the PaaS benefits of Azure SQL Database but adds additional capabilities like native virtual network support https://learn.microsoft.com/en-us/azure/azure-sql/azure-sql-iaas-vs-paas-what-is-overview .
For additional details on Azure SQL Managed Instance, you can refer to Azure SQL Managed Instance Documentation.
SQL Server on Azure Virtual Machines
SQL Server on Azure Virtual Machines falls into the category of Infrastructure-as-a-Service (IaaS) and is best for applications that require complete control over the SQL Server environment. This option provides the ability to use full versions of SQL Server in the cloud without having to manage any on-premises hardware.
- SQL Server Compatibility: Full SQL Server access and feature compatibility to migrate your SQL Server instances to Azure https://learn.microsoft.com/en-us/azure/azure-sql/azure-sql-iaas-vs-paas-what-is-overview .
- Manageability: When you register your SQL Server on Azure VM with the SQL IaaS Agent extension, you unlock several management features, such as automated backup, patching, and Azure Key Vault integration https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/doc-changes-updates-release-notes-whats-new-archive .
- Flexibility: Offers the flexibility to change SQL Server versions or editions and configure SQL Server settings like tempdb from the Azure portal https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/doc-changes-updates-release-notes-whats-new-archive .
For more information on SQL Server on Azure Virtual Machines, visit SQL Server on Azure VMs Documentation.
Each of these products is designed to provide a tailored SQL Server experience in the cloud, with varying levels of control and management. Depending on the specific requirements of the workload, users can select the most appropriate Azure SQL service.
Identify considerations for relational data on Azure (20–25%)
Describe relational Azure data services
Identify Azure Database Services for Open-Source Database Systems
Azure offers a variety of database services that support open-source database systems, providing scalability, high availability, and performance. Below are some of the key Azure services tailored for open-source databases:
Azure Managed Instance for Apache Cassandra
- Overview: Azure Managed Instance for Apache Cassandra is a service that allows you to manage instances of open-source Apache Cassandra datacenters deployed in Azure. It is designed for scenarios requiring scalability and high availability without compromising performance https://learn.microsoft.com/en-AU/azure/managed-instance-apache-cassandra/faq .
- Use Cases: This service is ideal for mission-critical data due to its linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure. It can be utilized entirely in the cloud or as part of a hybrid cloud and on-premises cluster https://learn.microsoft.com/en-AU/azure/managed-instance-apache-cassandra/faq .
- Benefits: Users can enjoy the fine-grained configuration and control of open-source Apache Cassandra with the added advantage of not having to deal with maintenance overhead https://learn.microsoft.com/en-AU/azure/managed-instance-apache-cassandra/faq .
- Additional Information: For more details, visit the Azure Managed Instance for Apache Cassandra page.
Azure Database for MySQL
- Overview: Azure Database for MySQL is a fully managed database service that supports Data-in replication, allowing synchronization of data between Azure Database for MySQL flexible server and different cloud providers https://learn.microsoft.com/en-AU/azure/mysql/flexible-server/concepts-data-in-replication .
- Migration: Customers can migrate with minimal downtime using open-source tools such as MyDumper/MyLoader. Data-in replication enables a selective cutover of production load from the source to the destination database https://learn.microsoft.com/en-AU/azure/mysql/flexible-server/concepts-data-in-replication .
- Additional Information: For migration scenarios, the Azure Database Migration Service is recommended https://learn.microsoft.com/en-AU/azure/mysql/flexible-server/concepts-data-in-replication .
Azure Database for PostgreSQL
- Overview: Azure Database for PostgreSQL – Flexible Server is the next generation of the service that brings advancements in computation, availability, scalability, and performance capabilities in the Azure database landscape https://learn.microsoft.com/en-AU/azure/postgresql/single-server/whats-happening-to-postgresql-single-server .
- Transition: The Single Server offering has been retired and upgraded to the Flexible Server to incorporate customer feedback and new advancements https://learn.microsoft.com/en-AU/azure/postgresql/single-server/whats-happening-to-postgresql-single-server .
- Additional Information: For more information, visit the Azure Database for PostgreSQL - Flexible Server page.
Azure Cosmos DB for NoSQL
- Overview: Azure Cosmos DB for NoSQL is a globally distributed, multi-model database service that offers turnkey global distribution, multi-master replication, and support for multiple NoSQL choices https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/benchmarking-framework .
- Performance Benchmarking: The benchmarking framework for Azure Databases simplifies the process of measuring performance with popular open-source benchmarking tools. For Azure Cosmos DB for NoSQL, it implements best practices for the Java SDK and uses the open-source YCSB tool https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/benchmarking-framework .
- Additional Information: To familiarize yourself with the framework and implement a read workload, refer to the benchmarking framework for Azure Databases and the best practices for the Java SDK in Azure Cosmos DB for NoSQL https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/benchmarking-framework .
These Azure services provide robust solutions for deploying and managing open-source databases in the cloud, ensuring that users can leverage the benefits of Azure’s infrastructure while maintaining the flexibility and control of open-source database systems.
Describe considerations for working with non-relational data on Azure (15–20%)
Describe capabilities of Azure storage
Describe Azure Blob Storage
Azure Blob storage is a service provided by Microsoft Azure that allows for the storage of large amounts of unstructured data, such as text or binary data. It is designed to serve different needs, such as serving images or documents directly to a browser, storing files for distributed access, streaming video and audio, writing to log files, or storing data for backup and restore, disaster recovery, and archiving.
Components of Azure Blob Storage
Storage Account: This is the fundamental container for Azure storage services. To use Azure Blob storage, you must first create a storage account. It is important to note that SQL Server is indifferent to the type of storage redundancy chosen. Azure Blob storage supports various redundancy options like LRS, ZRS, GRS, RA-GRS, and more, for both page blobs and block blobs https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/azure-storage-sql-server-backup-restore-use .
Container: A container acts as a directory for blobs and can store an unlimited number of blobs. Before you can back up a SQL Server to Azure Blob storage, you need to have at least the root container in place https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/azure-storage-sql-server-backup-restore-use .
Blob: Blobs are the individual files that you store in Azure Blob storage. They can be of any type and size, and are accessible via a specific URL format https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/azure-storage-sql-server-backup-restore-use .
Types of Blobs
Azure Blob storage offers different types of blobs to cater to various use cases:
- Block Blobs: Ideal for storing text or binary files, and for uploading large files efficiently.
- Append Blobs: Optimized for append operations, making them suitable for scenarios such as logging data from virtual machines.
- Page Blobs: Designed for frequent read/write operations and are used primarily as the backing storage for Azure Virtual Machine disks.
Accessing and Managing Azure Blob Storage
Azure Blob storage can be accessed and managed using Azure’s web-based portal, Azure CLI, Azure PowerShell, or Azure Storage SDKs for different programming languages. For Java, for example, Microsoft recommends using Version 12 of the storage client library, which supports Blob, Queue, File, and Data Lake services https://learn.microsoft.com/java/api/overview/azure/storage .
Security and Access Control
Azure provides various methods to authorize access to Blob storage, such as using an account key or a connection string. For more detailed guidance on how to authorize access using different programming languages, you can refer to the following resources:
- .NET https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-configure-connection-string
- Java https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-configure-connection-string
- JavaScript https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-configure-connection-string
- Python https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-configure-connection-string
Pricing and Account Types
Azure Storage offers several types of storage accounts, each supporting different features and having its own pricing model. For most scenarios, Microsoft recommends using the Standard general-purpose v2 account type, which supports Blob Storage, Queue Storage, Table Storage, and Azure Files with various redundancy options https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-account-overview .
For more information on Azure Blob storage, you can visit the following links:
- How to use Azure Blob storage https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/azure-storage-sql-server-backup-restore-use
- Understanding Block and Page Blobs https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/azure-storage-sql-server-backup-restore-use
- Azure SDK Releases page https://learn.microsoft.com/java/api/overview/azure/storage
- Azure Storage redundancy https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-account-overview
- Introduction to Data Lake Storage Gen2 https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-account-overview
Azure Blob storage is a versatile and scalable solution for storing large amounts of unstructured data in the cloud, providing a range of services and features to meet the needs of various applications and scenarios.
Describe considerations for working with non-relational data on Azure (15–20%)
Describe capabilities of Azure storage
Azure File Storage Overview
Azure File storage is a service that offers shared storage for applications using the standard SMB (Server Message Block) protocol. It is designed to enable cloud or on-premises deployments to share file data across application components via mounted shares, and it supports both Windows and Linux operating systems.
Key Features of Azure File Storage:
Shared Access: Azure Files allows multiple VMs to share the same files with read and write access. This can be useful for application configurations, diagnostic data, or job results that need to be accessed from various locations.
Compatibility: It supports industry-standard SMB protocol, meaning that most existing applications or services that use standard file system APIs can use Azure File storage without any modifications.
Fully Managed: As a fully managed service, Azure Files eliminates the need to manage hardware or an OS for file sharing. This simplifies maintenance and management tasks.
Scripting and Tool Support: Azure Files can be accessed and managed using PowerShell and Azure CLI, and it is supported by Azure Storage Client Libraries and Azure Storage REST API.
Resiliency: Azure Files offers different levels of redundancy to ensure data is highly available and durable. Options include locally redundant storage (LRS), geo-redundant storage (GRS), and zone-redundant storage (ZRS).
Integration with Azure Services: Azure Files can be integrated with other Azure services such as Azure Backup and Azure File Sync, enhancing its capabilities for disaster recovery and hybrid storage scenarios.
Types of Azure File Storage Accounts:
Standard File Shares: This is the standard storage account type for Azure Files and is recommended for general file storage needs. It supports all Azure Files features and redundancy options including LRS, GRS, and ZRS https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-account-overview .
Premium File Shares: Designed for enterprise or high-performance scale applications, premium file shares use solid-state drives (SSDs) for low latency and high throughput. It is recommended for scenarios that require consistent performance and low latency https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-account-overview .
Access and Security:
Authorization Options: Azure File storage supports various authorization options including Shared Key, Shared Access Signature (SAS), and integration with Microsoft Entra ID for Azure Active Directory (Azure AD) based access https://learn.microsoft.com/en-AU/azure/storage/tables/../common/authorize-data-access .
Network Security: To secure access to file shares, Azure Storage firewalls and virtual networks can be configured. This ensures that only authorized network traffic can access the storage account https://learn.microsoft.com/en-us/azure/azure-sql/database/database-import-export-azure-services-off .
Performance Considerations:
For optimal performance, it is recommended to use Azure Files when high throughput and low latency are required. Azure Files operates with the filesystem, allowing direct access to file shares https://learn.microsoft.com/en-us/azure/azure-sql/database/database-import-export-azure-services-off .
Cost Considerations:
Azure Files offers a flexible pricing model based on the chosen performance tier (standard or premium) and the redundancy option. To manage costs effectively, it is important to select the appropriate tier and redundancy level based on the application’s performance and availability requirements https://learn.microsoft.com/en-AU/azure/storage/tables/../common/storage-account-overview .
Additional Resources:
- For more information on Azure File storage, visit the Azure Files documentation.
- To learn about transferring .BACPAC files to and from Azure File storage, refer to Transfer data with AzCopy and file storage.
- For details on configuring Azure Storage firewalls and virtual networks, see Configure Azure Storage firewalls and virtual networks.
Azure File storage is a versatile and secure solution for managing file shares in the cloud, offering seamless integration with existing systems and a range of options to meet various performance and security needs.
Describe considerations for working with non-relational data on Azure (15–20%)
Describe capabilities of Azure storage
Describe Azure Table Storage
Azure Table Storage is a service that offers structured NoSQL data storage in the cloud, allowing for the storage of large amounts of non-relational data. This service is designed to store structured data at a massive scale in a schemaless fashion, which means that the data can be adapted easily as the needs of your application change over time https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
The core unit of data in Azure Table Storage is the “table,” which can be used to store datasets such as user data for web applications, address books, device information, or any other metadata required by a service. Each table stores data as entities, which are a set of properties, similar to rows in a relational database. A storage account can contain any number of tables, subject to the capacity limits of the account https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
Azure Table Storage is known for its fast and cost-effective access to data, making it suitable for many types of applications. It is often more economical than traditional SQL storage for similar volumes of data due to its schemaless design and the nature of its storage https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
The Table Storage API is a REST API that allows for working with tables and the data within them. This API is applicable to both Azure Table Storage and the Table API of Azure Cosmos DB, which offers additional features such as higher performance, global distribution, and automatic secondary indexes https://learn.microsoft.com/rest/api/storageservices/table-service-rest-api .
For developers, Azure provides a unified Azure Tables SDK that supports both Azure Table storage and Azure Cosmos DB for Table. This SDK simplifies the development process by providing a consistent set of tools for interacting with table data across both services https://learn.microsoft.com/en-AU/azure/storage/tables/table-storage-overview .
For monitoring and managing the performance and availability of Azure Table Storage, Azure Monitor can be used. It generates monitoring data for Azure resources, which can be analyzed and alerted upon to ensure the smooth operation of applications and business processes that rely on Azure Table Storage https://learn.microsoft.com/en-AU/azure/storage/tables/monitor-table-storage .
When querying data, it is possible to specify a range within a partition to retrieve a subset of entities. This can be done by combining a partition key filter with a row key filter, allowing for efficient data retrieval that matches specific criteria https://learn.microsoft.com/en-AU/azure/cosmos-db/table/how-to-use-c-plus .
For additional information on Azure Table Storage, you can refer to the following resources: - Azure Table Storage Guide - Azure Cosmos DB for Table - Azure Tables SDK Announcement - Serverless Mode in Azure Cosmos DB - Feature Differences Between Table API and Azure Table Storage
Please note that the URLs provided are for additional information and are not meant to be included in the study guide as explicit references to the exam.
Describe considerations for working with non-relational data on Azure (15–20%)
Describe capabilities and features of Azure Cosmos DB
Identify Use Cases for Azure Cosmos DB
Azure Cosmos DB is a globally distributed, multi-model database service that offers a wide range of use cases due to its flexibility, scalability, and performance. Below are some of the key scenarios where Azure Cosmos DB is particularly well-suited:
Serverless Applications: Azure Cosmos DB’s serverless mode is ideal for development, testing, or any application with sporadic traffic patterns. It operates on a consumption-based model, ensuring you only pay for the resources you use, with no minimum fees. This makes it cost-effective for workloads that do not require continuous throughput capacity https://learn.microsoft.com/en-AU/azure/cosmos-db/optimize-costs .
User-Generated Content (UGC): For applications dealing with UGC such as chat sessions, tweets, blog posts, ratings, and comments, Azure Cosmos DB provides a flexible schema that can handle the semi-structured nature of this data. It allows for rapid development and iteration, as new data properties can be added without the need for complex transformations https://learn.microsoft.com/en-AU/azure/cosmos-db/use-cases .
Social Media Applications: Azure Cosmos DB is well-suited for social media applications that need to adapt to changing data schemas and require immediate data availability for querying. Its automatic indexing ensures that data is always ready for retrieval, providing the necessary flexibility for these dynamic environments https://learn.microsoft.com/en-AU/azure/cosmos-db/use-cases .
Global Distribution: Applications that require global reach can benefit from Azure Cosmos DB’s ability to distribute data across multiple regions. This ensures low-latency access to data regardless of where the end-users are located, enabling a consistent experience worldwide https://learn.microsoft.com/en-AU/azure/cosmos-db/use-cases .
Scalability: For applications with unpredictable usage patterns, Azure Cosmos DB offers the ability to scale out by adding data partitions or creating additional accounts across multiple regions. This flexibility is crucial for applications that experience sudden spikes in traffic or need to grow with user demand https://learn.microsoft.com/en-AU/azure/cosmos-db/use-cases .
For more detailed information on Azure Cosmos DB use cases, you can refer to the following resources: - Common Azure Cosmos DB use cases https://learn.microsoft.com/en-AU/azure/cosmos-db/social-media-apps https://learn.microsoft.com/en-AU/azure/cosmos-db/whitepapers . - Azure Cosmos DB serverless https://learn.microsoft.com/en-AU/azure/cosmos-db/optimize-costs . - Azure Regions for Cosmos DB service availability https://learn.microsoft.com/en-AU/azure/cosmos-db/use-cases .
These resources provide additional insights into how Azure Cosmos DB can be leveraged for various application scenarios, helping to understand its capabilities and how it can fit into different architectural designs.
Describe an analytics workload on Azure (25–30%)
Describe common elements of large-scale analytics
Considerations for Data Ingestion and Processing
When designing a system for data ingestion and processing, several key considerations must be taken into account to ensure efficient, secure, and reliable handling of data. Below are some of the primary considerations:
- Data Import Sequence and Transformation:
- Determine the order in which different data types should be ingested.
- Consider the necessary transformations to handle various data formats and volumes.
- Design for continuous data refresh to keep the data up-to-date.
- Ensure the uniqueness of imported records to avoid duplication.
- Manage the velocity of data, especially in scenarios involving IoT devices.
- Securely access remote data sources, whether hosted in the cloud or on-premises locations https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview .
- Data Export:
- Explore options for exporting calculated data to other systems for further processing https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview .
- Data Security:
- Implement measures to prevent unauthorized access and modification of data https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview .
- Data Auditing and Traceability:
- Ensure accuracy, reliability, and compliance in the measurement, reporting, and management of data https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview .
- Custom Dimensions:
- Consider how to associate activity data with operational contextual information, such as production lines and types used in manufacturing https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview .
- User Interface for Data Ingestion:
- Provide a simplified and guided user interface to limit user errors during data ingestion.
- Utilize flexible ingestion methods and standardized mechanisms across different environmental data categories https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-ingestion-design .
- Decoupling of Data Processes:
- Separate data transformation, data mapping, and data import to reduce the risk of human errors https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-ingestion-design .
- Data Volume and Ingestion Rate:
- Be aware of the recommended ingestion rates for materialized views and the performance implications of exceeding those rates https://learn.microsoft.com/azure/data-explorer/kusto/management/materialized-views/materialized-view-overview .
- Number of Materialized Views in a Cluster:
- Understand the resource competition among materialized views and adjust the capacity policy accordingly https://learn.microsoft.com/azure/data-explorer/kusto/management/materialized-views/materialized-view-overview .
- Materialized View Definition:
- Define materialized views according to query best practices for optimal performance https://learn.microsoft.com/azure/data-explorer/kusto/management/materialized-views/materialized-view-overview .
- Data Ingestion Options into a Warehouse:
- Consider the different options for data ingestion, such as COPY (Transact-SQL), data pipelines, dataflows, and cross-warehouse ingestion, and determine the best fit for your needs https://learn.microsoft.com/en-us/fabric/data-warehouse/guidelines-warehouse-performance .
For additional information on data ingestion and processing, the following resources can be consulted: - Data Import Considerations https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview - Data Export Design https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview - Data Security Design https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview - Data Auditing and Traceability https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview - Custom Dimensions Design https://learn.microsoft.com/en-us/industry/well-architected/sustainability/sustainability-manager-data-management-overview - Materialized Views Capacity Policy https://learn.microsoft.com/azure/data-explorer/kusto/management/materialized-views/materialized-view-overview - Data Ingestion Options https://learn.microsoft.com/en-us/fabric/data-warehouse/guidelines-warehouse-performance
By considering these aspects, organizations can design a robust data ingestion and processing system that meets their operational needs and supports their strategic objectives.
Describe an analytics workload on Azure (25–30%)
Describe common elements of large-scale analytics
Options for Analytical Data Stores
Analytical data stores are designed to facilitate efficient data analysis and are optimized for read-heavy workloads. They differ from transactional data stores, which are optimized for write operations and transactional integrity. Below are some options and considerations for analytical data stores:
Analytical Time-to-Live (ATTL)
Definition: ATTL is a property that determines how long data should be retained in an analytical store. It is a crucial setting for managing the lifecycle of data within Azure Cosmos DB’s analytical store https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Configuration Options:
- Disabled: Setting ATTL to
0orNULLdisables the analytical store, meaning no data is replicated from the transactional store https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction . - Infinite Retention: An ATTL value of
-1indicates that the analytical store will retain all historical data indefinitely, regardless of the transactional store’s retention policy https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction . - Finite Retention: A positive integer value for ATTL specifies that items will expire from the analytical store a certain number of seconds after their last modification in the transactional store https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
- Disabled: Setting ATTL to
Operational Considerations:
- ATTL can be updated after the analytical store is enabled https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
- ATTL is set at the container level, unlike transactional TTL (TTTL), which can be set at both the container and item levels https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
- To ensure longer retention of operational data in the analytical store, ATTL should be set equal to or greater than TTTL https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
- Data that exists only in the analytical store due to a larger ATTL than TTTL is read-only https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Enabling Analytical Store: The analytical store can be enabled via the Azure portal, Azure Management SDKs, PowerShell, or Azure CLI by setting the ATTL to either
-1or a positive integer https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Pricing Considerations
Consumption-Based Model: The analytical store follows a consumption-based pricing model, where costs are associated with storage volume, analytical write operations, and analytical read operations https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Accessing Data: Data in the analytical store can only be accessed through Azure Synapse Link, which utilizes Azure Synapse Analytics Spark pools and serverless SQL pools https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Cost Estimation Tools: The Azure Cosmos DB Capacity planner can be used to estimate analytical storage and write operation costs. However, read operation estimates are not included and depend on the specific analytical workload https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction .
Data Management
Data Synchronization: Updates and deletes in the transactional store are automatically reflected in the analytical store, ensuring consistency between the two https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link-frequently-asked-questions .
Historical Data: The analytical store can be configured to retain historical versions of items based on the analytical TTL settings, allowing for comprehensive data analysis over time https://learn.microsoft.com/en-AU/azure/cosmos-db/synapse-link-frequently-asked-questions .
For additional information on configuring and managing analytical data stores, you can refer to the following resources: - Configure Analytical TTL on a Container https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction - Analytical Store Overview https://learn.microsoft.com/en-AU/azure/cosmos-db/nosql/modeling-data - Azure Cosmos DB Pricing Details https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction - Azure Synapse Analytics Pricing Details https://learn.microsoft.com/en-AU/azure/cosmos-db/analytical-store-introduction
These resources provide in-depth guidance on the implementation, pricing, and management of analytical data stores within Azure Cosmos DB and how to access them using Azure Synapse Link.
Describe an analytics workload on Azure (25–30%)
Describe common elements of large-scale analytics
Azure Services for Data Warehousing
Data warehousing is a critical component of business intelligence that involves the storage and analysis of large volumes of data. Azure offers a suite of services that cater to various aspects of data warehousing, each with its unique features and capabilities.
Azure Synapse Analytics
Azure Synapse Analytics is an analytics service that brings together big data and data warehousing. It allows users to query data using either serverless on-demand or provisioned resources. Synapse Analytics provides a unified experience to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs. More information can be found at Azure Synapse Analytics Overview https://learn.microsoft.com/azure/data-factory/connector-azure-sql-database .
Azure Databricks
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. It provides a collaborative environment with a workspace for data scientists, data engineers, and business analysts to work together. Databricks integrates with Azure services to provide a one-click setup, streamlined workflows, and an interactive workspace that enables collaboration between data scientists, data engineers, and business analysts. To create a Spark cluster in Azure Databricks, you can follow the instructions on Deploying Azure Databricks in your Azure Virtual Network https://learn.microsoft.com/en-AU/azure/cosmos-db/../managed-instance-apache-cassandra/deploy-cluster-databricks .
Microsoft Fabric
Microsoft Fabric is an all-in-one analytics solution that covers a wide range of data-related tasks, including data movement, data science, real-time analytics, business intelligence, and reporting. It provides a comprehensive set of tools for enterprises to manage their data warehousing needs. You can start a new trial for Microsoft Fabric at Microsoft Fabric Trial https://learn.microsoft.com/azure/data-factory/connector-azure-sql-database .
Azure HDInsight
Azure HDInsight is a cloud service that makes it easy, fast, and cost-effective to process massive amounts of data. It supports a broad range of scenarios such as ETL, Data Warehousing, Machine Learning, and IoT. However, it’s important to note that Data Factory in Microsoft Fabric does not currently support Azure HDInsight on AKS Trino in data pipelines https://learn.microsoft.com/en-us/fabric/data-factory/connector-azure-hdinsight-on-aks-trino-overview .
Azure Data Factory
Azure Data Factory is a cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and data transformation. It enables users to create, schedule, and manage data pipelines that can ingest data from disparate data stores. It offers a code-free UI for intuitive authoring and single-pane-of-glass monitoring and management. You can learn more about how to use Copy Activity in Azure Data Factory to copy data from and to Azure SQL Database at Azure Data Factory Introduction https://learn.microsoft.com/azure/data-factory/connector-azure-sql-database .
Each of these services plays a vital role in the data warehousing ecosystem within Azure, providing tools and capabilities to handle large-scale data processing and analytics. They can be used individually or in combination to build a comprehensive data warehousing solution that meets the specific needs of an organization.
Describe an analytics workload on Azure (25–30%)
Describe consideration for real-time data analytics
Batch vs. Streaming Data
Batch data processing is a method where data is collected over a period of time and then processed in large, discrete chunks (batches) at a scheduled time or when the batch reaches a certain size. This approach is often used when it is acceptable to have some latency between data collection and data availability for analysis. Batch processing is suitable for scenarios where the data volume is large, and the processing can be deferred until the complete set of data is available. It is also useful for complex computations that do not require immediate results.
On the other hand, streaming data processing involves continuous ingestion and processing of data records individually or in small batches as soon as they are generated. This method is ideal for scenarios where it is necessary to respond quickly to data as it arrives, such as in real-time analytics, monitoring, and event-driven applications. Streaming data often has a time component that affects data preparation tasks, and it is characterized by low-latency processing, which allows for immediate insights and actions based on the incoming data.
Key differences include:
- Latency: Batch processing can have high latency due to the time taken to collect and process the entire batch of data. Streaming processing has low latency, as data is processed in near real-time.
- Data Volume: Batch processing is designed to handle large volumes of data efficiently, while streaming processing deals with continuous flows of data in smaller quantities.
- Complexity: Batch jobs can be more complex and compute-intensive, as they are not constrained by the need for immediate processing. Streaming processing requires a more streamlined approach to handle the continuous flow of data.
- Timeliness: Streaming data processing provides more timely insights and enables immediate action, which is crucial for time-sensitive applications.
For more information on batch and streaming data processing, you can refer to the following resources:
- Delta Lake’s documentation on batch and streaming unification: Delta Batch and Streaming https://learn.microsoft.com/en-us/fabric/data-engineering/runtime-1-2 .
- Azure Stream Analytics, a real-time analytics and complex event-processing engine: Azure Stream Analytics Introduction https://learn.microsoft.com/en-us/fabric/real-time-analytics/data-connectors/data-connectors .
- Structured streaming UI in Spark for monitoring streaming metrics: Structured Streaming Tab in Spark UI https://learn.microsoft.com/en-us/fabric/data-engineering/lakehouse-streaming-data .
These resources provide a deeper understanding of how batch and streaming data processing work and how they can be applied in different scenarios.
Describe an analytics workload on Azure (25–30%)
Describe consideration for real-time data analytics
Microsoft Cloud Services for Real-Time Analytics
Real-time analytics is the process of analyzing data as soon as it becomes available, allowing businesses to make immediate decisions based on the most current information. Microsoft offers several cloud services that enable real-time analytics, providing insights into data with minimal latency. Below are the key services that facilitate real-time analytics in the Microsoft cloud ecosystem:
Azure Event Hubs
Azure Event Hubs is a highly scalable data streaming platform and event ingestion service. It can receive and process millions of events per second, which makes it an ideal entry point for an event pipeline aiming to perform real-time analytics on the ingested data. Event Hubs can be used in conjunction with other services to enable real-time analytics https://learn.microsoft.com/en-us/azure/azure-sql/identify-query-performance-issues https://learn.microsoft.com/en-us/azure/azure-sql/database/metrics-diagnostic-telemetry-logging-streaming-export-configure .
Azure Stream Analytics
Azure Stream Analytics is a real-time analytics and complex event-processing engine that is designed to analyze and process high volumes of fast streaming data from multiple sources simultaneously. Patterns can be identified, and insights can be derived from the data as it flows, which can then be visualized in reports and dashboards. Stream Analytics can be connected to Azure Event Hubs for data input and Power BI for output to create real-time analytics dashboards https://learn.microsoft.com/en-us/azure/azure-sql/identify-query-performance-issues https://learn.microsoft.com/en-us/azure/azure-sql/database/metrics-diagnostic-telemetry-logging-streaming-export-configure https://learn.microsoft.com/en-us/power-bi/connect-data/refresh-data .
Power BI
Power BI is a business analytics service that provides interactive visualizations and business intelligence capabilities with an interface simple enough for end users to create their reports and dashboards. It can be used to visualize the data being processed by Azure Stream Analytics in real-time, providing a powerful tool for building real-time analytics dashboards https://learn.microsoft.com/en-us/azure/azure-sql/identify-query-performance-issues https://learn.microsoft.com/en-us/azure/azure-sql/database/metrics-diagnostic-telemetry-logging-streaming-export-configure https://learn.microsoft.com/en-us/power-bi/connect-data/refresh-data .
Azure Data Explorer
Azure Data Explorer is a fast and highly scalable data exploration service for log and telemetry data. It offers real-time analysis on large volumes of data streaming from applications, websites, IoT devices, and more. Azure Data Explorer uses the Kusto Query Language (KQL) for querying massive amounts of data in near real-time https://learn.microsoft.com/en-us/fabric/real-time-analytics/realtime-analytics-compare .
Real-Time Analytics in Microsoft Fabric
Real-Time Analytics is a data analytics Software as a Service (SaaS) experience within the Microsoft Fabric offering. It shares the same core engine as Azure Data Explorer, providing identical core capabilities but with different management behavior. Real-Time Analytics also offers capabilities such as Eventstreams, which are managed at the workspace level https://learn.microsoft.com/en-us/fabric/real-time-analytics/realtime-analytics-compare .
For more detailed information on setting up and using these services for real-time analytics, you can refer to the following resources: - Stream Analytics and Power BI: A real-time analytics dashboard for streaming data https://learn.microsoft.com/en-us/azure/azure-sql/identify-query-performance-issues https://learn.microsoft.com/en-us/azure/azure-sql/database/metrics-diagnostic-telemetry-logging-streaming-export-configure https://learn.microsoft.com/en-us/power-bi/connect-data/refresh-data . - What is Real-Time Analytics in Fabric? https://learn.microsoft.com/en-us/fabric/real-time-analytics/realtime-analytics-compare .
These services, when used together, provide a comprehensive solution for processing and analyzing data in real-time, enabling businesses to gain timely insights and make informed decisions quickly.
Describe an analytics workload on Azure (25–30%)
Describe data visualization in Microsoft Power BI
Identify Capabilities of Power BI
Power BI is a suite of business analytics tools that deliver insights throughout your organization. Below are some of the key capabilities of Power BI:
Power BI Service and Power BI in Teams
- Artificial Intelligence Integration: Power BI incorporates artificial intelligence capabilities that allow users to work on reports directly within the Power BI service and Power BI in Teams https://learn.microsoft.com/en-us/power-bi/collaborate-share/../consumer/business-user-teams-create-reports .
Power BI Desktop
- Data Connectivity and Preparation: Power BI Desktop, also known as Desktop, is a free Windows application that enables users to connect to, transform, and visualize data. It is primarily used by report designers and administrators https://learn.microsoft.com/en-us/power-bi/developer/embedded/pbi-glossary .
- URL for more information: What is Power BI https://learn.microsoft.com/en-us/power-bi/developer/embedded/pbi-glossary .
Power BI Visuals
- Custom Visuals Development: Power BI allows the creation of custom visuals with specific properties and settings. These settings include declaring supported features, objects, properties, and data view mapping https://learn.microsoft.com/en-us/power-bi/developer/visuals/visual-project-structure .
- URL for capabilities: Power BI Visuals Capabilities https://learn.microsoft.com/en-us/power-bi/developer/visuals/visual-project-structure .
- URL for data view mapping: Data View Mappings https://learn.microsoft.com/en-us/power-bi/developer/visuals/visual-project-structure .
Power BI Embedded Analytics
- Integrated Analytics Experience: Power BI embedded analytics provides a fully integrated experience with full API support and automatic authentication. Reports can be hosted in apps as well as web pages https://learn.microsoft.com/en-us/power-bi/developer/embedded/embedded-analytics-power-bi .
- Feature Parity with Power BI Premium: Power BI Embedded offers the same features as Power BI Premium, allowing for the automation of monitoring, management, and deployment of analytics https://learn.microsoft.com/en-us/power-bi/developer/embedded/embedded-analytics-power-bi .
- URL for Power BI Premium features: Power BI Premium Features https://learn.microsoft.com/en-us/power-bi/developer/embedded/embedded-analytics-power-bi .
- Two Solutions Offered:
- Embed for your customers
- Embed for your organization https://learn.microsoft.com/en-us/power-bi/developer/embedded/embedded-analytics-power-bi .
Power BI and Log Analytics
- Data Export and Authentication: Power BI can export data from Log Analytics and requires authentication to connect and retrieve data https://learn.microsoft.com/en-us/power-bi/connect-data/create-dataset-log-analytics .
- Credential Management: Users have the option to continue using previously used sign-in details or to use their current sign-in credentials for connections, which affects the data visibility in the semantic model https://learn.microsoft.com/en-us/power-bi/connect-data/create-dataset-log-analytics .
- URL for establishing connection: The process of establishing a connection to Log Analytics is detailed in the documentation, including the importance of credential choice https://learn.microsoft.com/en-us/power-bi/connect-data/create-dataset-log-analytics .
Please note that the URLs provided are for additional information and are part of the official Microsoft documentation. They offer a deeper dive into the capabilities and features of Power BI.
Describe an analytics workload on Azure (25–30%)
Describe data visualization in Microsoft Power BI
Features of Data Models in Power BI
Power BI data models are essential for transforming raw data into meaningful insights. Here are some of the key features that make Power BI data models powerful tools for data analysis and visualization:
Automated Machine Learning: Power BI allows users to create and apply binary prediction models using automated machine learning. This feature enables users to predict outcomes based on data, such as the purchase intent of online shoppers, by training a machine learning model directly within Power BI https://learn.microsoft.com/en-us/power-bi/create-reports/../connect-data/service-tutorial-build-machine-learning-model .
Dataflows: Dataflows in Power BI enable users to create and manage data preparation pipelines. These dataflows can be used to train machine learning models, and they can also be applied to entities within Power BI for scoring and generating predictions https://learn.microsoft.com/en-us/power-bi/create-reports/../connect-data/service-tutorial-build-machine-learning-model .
Featured Tables: Featured tables in Power BI facilitate the integration of enterprise data into Microsoft Excel. They allow users to easily add data from Power BI semantic models into Excel sheets, enhancing the data analysis capabilities of Excel with the power of Power BI https://learn.microsoft.com/en-us/power-bi/collaborate-share/service-excel-featured-tables .
Advanced AI Integration: Power BI integrates advanced AI capabilities, allowing users to apply artificial intelligence to their dataflows. This can include features like text analytics, image recognition, and automated machine learning models https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
DirectQuery with Dataflows: This feature allows users to connect directly to their dataflow without having to import the data. It enables real-time data analysis and reporting, which is crucial for timely decision-making https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
Hybrid Tables: Hybrid tables are a preview feature that combines incremental refresh with real-time data. This allows for a more dynamic and up-to-date data model that can reflect the latest changes in the data source https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
Model Size Limit: Power BI sets limits on the memory footprint of a single Power BI semantic model, which varies depending on the type of service (Premium, Premium Per User, or Embedded). This ensures that models are optimized for performance https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
Endorsement: Power BI allows users to promote or certify semantic models, which is known as endorsement. Endorsed models are prioritized in Excel’s Data Types Gallery, with certified semantic models listed first https://learn.microsoft.com/en-us/power-bi/collaborate-share/service-create-excel-featured-tables .
For additional information on these features, you can refer to the following URLs:
- Automated Machine Learning: Power BI Dataflows https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
- Featured Tables: Create Excel Featured Tables in Power BI https://learn.microsoft.com/en-us/power-bi/collaborate-share/service-excel-featured-tables .
- Advanced AI: Advanced AI with Dataflows https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
- DirectQuery with Dataflows: Use DirectQuery with Dataflows in Power BI https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
- Hybrid Tables: Hybrid Tables in Power BI https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
- Model Size Limit: Power BI Premium Capacities and SKUs https://learn.microsoft.com/en-us/power-bi/developer/embedded/../../enterprise/service-premium-features .
- Endorsement: Promote or Certify Semantic Models in Power BI https://learn.microsoft.com/en-us/power-bi/collaborate-share/service-create-excel-featured-tables .
These features collectively enhance the data modeling capabilities in Power BI, enabling users to create sophisticated and insightful reports and dashboards.
Describe an analytics workload on Azure (25–30%)
Describe data visualization in Microsoft Power BI
Identifying Appropriate Visualizations for Data
When selecting visualizations for data representation, it is essential to consider the nature of the data and the message you want to convey. Here are some guidelines to help you choose the most suitable visualizations:
Understand Data Types: Different types of data are best represented by different types of visualizations. For instance, geographic data may not be effectively displayed in a funnel chart or line chart https://learn.microsoft.com/en-us/power-bi/create-reports/../visuals/power-bi-report-add-visualizations-ii .
Consider the Visualization’s Purpose:
- To compare values, bar charts and column charts are effective.
- For showing trends over time, line charts or area charts are appropriate.
- Pie charts or donut charts can be used to display proportions of a whole .
Interactivity and Drill-Downs: Some visualizations offer interactive features such as drill-downs, which allow viewers to click on a region of a treemap, for example, to see more detailed data for that area .
Card Visualizations: These are used to display single numbers prominently, such as total sales or average order value https://learn.microsoft.com/en-us/power-bi/create-reports/sample-revenue-opportunities .
Choosing the Right Chart for Sequences: For visualizations that render sequences of values, such as time series data, line charts, time charts, and area charts are suitable. The x-axis typically represents time, and the y-axis represents the measured values https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator .
Customization: Power BI allows customization of visualizations, including tooltips, to enhance the understanding of the data presented https://learn.microsoft.com/en-us/power-bi/create-reports/sample-revenue-opportunities .
Q&A Feature: Power BI’s Q&A feature can assist in choosing the right visualization by analyzing structured data and selecting an appropriate visualization based on the query https://learn.microsoft.com/en-us/power-bi/create-reports/service-prepare-data-for-q-and-a .
For additional information on creating and customizing visualizations in Power BI, you can refer to the following resources: - Customize tooltips in Power BI https://learn.microsoft.com/en-us/power-bi/create-reports/sample-revenue-opportunities . - Add a query visualization in the web UI https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator . - Customize dashboard visuals https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator .
Remember, the key to effective data visualization is to ensure that the chosen visual communicates the data clearly and accurately, allowing the viewer to grasp the insights the data provides.
Describe an analytics workload on Azure (25–30%)
Describe data visualization in Microsoft Power BI
Identifying Appropriate Visualizations for Data
When selecting visualizations for data, it is essential to consider the type of data you are working with and the insights you aim to convey. Here are some guidelines to help you choose the most suitable visualizations:
- Understanding Data Types and Visualization
Compatibility
- Begin by selecting a field in the Data pane. Power BI will suggest a visualization type based on the field type you select https://learn.microsoft.com/en-us/power-bi/create-reports/../visuals/power-bi-report-add-visualizations-ii .
- Not all visualizations are suitable for every data type. For instance, geographic data may not be effectively represented in a funnel chart or line chart https://learn.microsoft.com/en-us/power-bi/create-reports/../visuals/power-bi-report-add-visualizations-ii .
- Exploring Data through Interactive Visualizations
- Interactive elements such as donut visualizations allow users to focus on specific data subsets by making selections directly in the visualization https://learn.microsoft.com/en-us/power-bi/create-reports/sample-employee-hiring-history .
- Visualizations like matrices can be converted into different types, such as clustered bar charts, to better suit the data being displayed https://learn.microsoft.com/en-us/power-bi/create-reports/sample-employee-hiring-history .
- Utilizing Card Visualizations for Key Metrics
- Card visualizations are effective for displaying single numbers, providing a clear view of important metrics like Opportunity Revenue and Opportunity Count https://learn.microsoft.com/en-us/power-bi/create-reports/sample-revenue-opportunities .
- Drilling Down into Data with Tree Diagrams
- Tree diagrams offer a hierarchical view of data, allowing users to drill down into specific regions or categories to analyze the finer details https://learn.microsoft.com/en-us/power-bi/create-reports/sample-revenue-opportunities .
- Choosing Visualizations for Sequences of Values
- For data that involves sequences, such as time series,
visualizations like
linechart,timechart, andareachartare appropriate https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator . - These visualizations typically require one column to represent the x-axis and one or more columns to represent the y-axis values https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator .
- For data that involves sequences, such as time series,
visualizations like
- Leveraging Q&A for Visualization Selection
- Power BI’s Q&A feature can automatically search structured data and select the right visualization for your question https://learn.microsoft.com/en-us/power-bi/create-reports/service-prepare-data-for-q-and-a .
- Optimizing and cleaning your data model enhances the Q&A feature’s ability to provide relevant visualizations and answers .
For more detailed guidance on selecting and customizing visualizations in Power BI, you can refer to the following resources: - Customize tooltips in Power BI https://learn.microsoft.com/en-us/power-bi/create-reports/sample-revenue-opportunities . - Add a query visualization in the web UI https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator . - Customize dashboard visuals https://learn.microsoft.com/azure/data-explorer/kusto/query/render-operator .
Remember, the key to effective data visualization is to match the visualization type to the data’s nature and the insights you wish to communicate. Experiment with different visualizations to find the one that makes your data easy to understand and explore.